
By Dor Laor and Avi Kivity
Linux containers
(This is part 2 of a 3-part series. Part 1 was published yesterday.)
Containers, which create isolated compartments at the operating system level instead of adding a separate hypervisor level, trace their history not to mainframe days, but to Unix systems.
FreeBSD introduced “jails” in 2000. There’s a good description of them in Jails: Confining the omnipotent root by Poul-Henning Kamp and Robert N. M. Watson. Solaris got its Zones in 2005. Both systems allowed for an isolated “root” user and root filesystem.
The containers we know today, Linux Containers, or LXC, are not a single monolithic system, but more of a concept, based on a combination of several different isolation mechanisms built into Linux at the kernel level. Linux Containers 1.0 was released earlier this year., but many of the underlying systems have been under development in Linux independently. Containers are not an all-or-nothing design decision, and it’s possible for different systems to work with them in different ways. LXC can use all of the following Linux features:
-
Kernel namespaces (ipc, uts, mount, pid, network and user)
-
AppArmor and SELinux profiles
-
Seccomp policies
-
Chroots (using pivot_root)
-
Kernel capabilities
-
Control groups (cgroups)
Although the combination can be complex, there are tools that make containers simple to use. For several years userspace tools such as LXC, libvirt allowed users to manage containers. However, containers didn’t really get picked up by the masses until the creation of Docker. Docker and systemd-nspawn can start containers with minimal configuration, or from the command line. The Docker developers deserve much credit for adding two powerful concepts above the underlying container complexity: a. Public image repository - immediate search and download of containers pre-loaded with dependencies, and b. Dead-simple execution - a one-liner command for running a container.
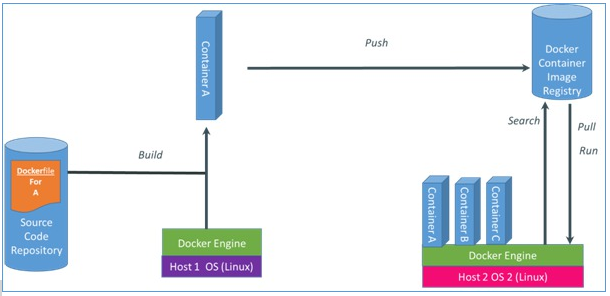
Docker gives container users a simple build process and a public repository system.
Container advantages
When deployed on a physical machine, containers can eliminate the need of running two operating systems, one on top of the other (as in traditional virtualization). It makes IO system calls almost native and the footprint is minimal. However, this comes with a cost as we will detail below. The rule of the thumb is that if you do not need multi-tenancy and you’re willing to do without a bunch of software defined features, containers on bare metal are perfect for you!
In production, Google uses containers extensively, starting more than two billion per week. Each container includes an application, built together with its dependencies, and containerization helps the company manage diverse applications across many servers.
Containers are an excellent case for development and test. It becomes possible to test some fairly complex setups, such as a version control system with hooks, or an SMTP server with spam filters, by running services in a container. Because a container can use namespaces to get a full set of port numbers, it’s easy to run multiple complex tests at a time. The systemd project even uses containers for testing their software, which manages an entire Linux system. Containers are highly useful for testing because of their fast startup time–you’re just invoking an isolated set of processes on an existing kernel, not booting an entire guest OS.
If you run multiple applications that depend on different versions of a dependency, then deploying each application within its own container can allow you to avoid dependency conflict problems. Containers in theory decouple the application from the operating system. We use the term ‘in theory’ because lots of care and thought should be given to maintaining your stack. For example, will your container combo be supported by the host OS vendor? Is your container up-to-date and does it include fixes for bugs such as ‘heartbleed’? Is your host fully updated, and does its kernel API provide the capabilities your application requires?
We highly recommend the use of containers whenever your environment is homogeneous:
-
No multitenancy
-
Application is always written with clustering in mind
-
Load balancing is achieved by killing running apps and re-spinning them elsewhere (as opposed to live migration)
-
No need to run different kernel versions
-
No underlying hypervisor (otherwise, you’re just adding a layer)
When the above apply, you will enjoy near bare-metal performance, a small footprint and fast boot time.
Container disadvantages: Security
It’s clear that a public cloud needs strong isolation separating tenant systems. All that an attacker needs is an email address and a credit card number to set up a hostile VM on the same hardware as yours. But strong isolation is also needed in private clouds behind the corporate firewall. Corporate IT won’t be keen to run sandbox42.interns.engr.example.com and payroll.example.com within the same security domain.
Hypervisors have a relatively simple security model. The interface between the guest and the hypervisor is well defined, based on real or virtual hardware specifications. Five decades of hypervisor development have helped to form a stable and mature interface. Large portions of the interface’s security are enforced by the physical hardware.
Containers, on the other hand, are implemented purely in software. All containers and their host share the same kernel. Nearly the entire Linux kernel had to undergo changes in order to implement isolation for resources such as memory management, network stack, I/O, the scheduler, and user namespaces. The Linux community is investing a lot of effort to improve and expand container support. However, rapid development makes it harder to stabilize and harden the container interfaces.
Container disadvantages: Software-defined data center
Hypervisors are the basis for the new virtualized data center. They allow us to perfectly abstract the hardware and play nicely with networking and storage. Today there isn’t a switch or a storage system without VM integration or VM-specific features.
Can a virtualized data center be based on containers in place of hypervisors? At almost all companies, no.. There will always be security issues with mounting SAN devices and filesystems from containers in different security domains. Yes, containers are a good fit for plenty of tasks but are restricted when it comes to sensitive areas such as you data center building blocks such as the storage and the network.
No one operating system, even Linux, will run 100% of the applications in the data center. There will always be diversity at the data center, and the existence of different operating systems will force the enterprise to keep the abstraction at the VM level.
Container disadvantages: Management
The long history of hypervisors means that the industry has developed a huge collection of tools for real-world administration needs.
Blogger Robert Moran shows a screenshot of CPU monitoring in VMware’s vSphere.
The underlying functionality for hypervisor management is also richer. All of the common hypervisors support “live migration” of guests from one host to another.
Hypervisors have become an essential tool in the community of practice around server administration. Corporate IT is in the process of virtualizing its diverse collection of servers, running modern and vintage Linux distributions, plus legacy operating systems, and hypervisor vendors including VMWare and Microsoft are enabling it.
Container disadvantages: Complexity
While containers take advantage of the power built into Linux, they share Linux’s complexity and diversity. For example, each Linux distribution standardizes on a different kernel version, and some use AppArmor while others use SELinux. Because containers are implemented using multiple isolation features at the OS level, the “containerization” features can vary by kernel version and platform.
The anatomy of a multi-tenant exploit
Let’s assume a cloud vendor, whether SaaS, IaaS, or PaaS, implements a service within a container. How would an attacker exploit it? The first stage would be to gain control of the application within the container. Many applications have flaws and the attacker would need to exploit an existing unpatched CVE in order to gain access to the container. IaaS even makes it simpler as the attacker already has a “root” shell inside a neighboring container.
The next stage would be to penetrate the kernel. Unfortunately, the kernel’s attack surface contains hundreds of system calls, and other vulnerabilities exist in the form of packets and file metadata that can jeopardize the kernel. Many attackers have access to zero-day exploits, unpublished local kernel vulnerabilities. (A typical “workflow” is to watch upstream kernel development for security-sensitive fixes, and figure out how to exploit them on the older kernels in production use.)
Once the hacker gains control of the kernel, it’s game over. All the other tenants’ data is exposed.
The list of exploitable bugs is always changing, and there will probably be more available by the time you read this. A few recent examples:
-
“An information leak was discovered in the Linux kernel’s SIOCWANDEV ioctl call. A local user with the CAP_NET_ADMIN capability could exploit this flaw to obtain potentially sensitive information from kernel memory.“ (CVE-2014-1444) Some container configurations have CAP_NET_ADMIN, while others don’t. Because it’s possible to set up containers in more or less restricted ways, individual sites need to check if they’re vulnerable. (Many LInux capabilities are equivalent to root because they can be used to obtain root access.)
-
“An information leak was discovered in the wanxl ioctl function in Linux. A local user could exploit this flaw to obtain potentially sensitive information from kernel memory.” (CVE-2014-1445)”
-
“An unprivileged local user with access to a CIFS share could use this flaw to crash the system or leak kernel memory. Privilege escalation cannot be ruled out (since memory corruption is involved), but is unlikely.“ (CVE-2014-0069)
Each individual vulnerability is usually fixed quickly, but there’s a constant flow of new ones for attackers to use. Linux filesystem developer Ted Ts’o wrote,
Something which is baked in my world view of containers (which I suspect is not shared by other people who are interested in using containers) is that given that the kernel is shared, trying to use containers to provide better security isolation between mutually suspicious users is hopeless. That is, it’s pretty much impossible to prevent a user from finding one or more zero day local privilege escalation bugs that will allow a user to break root. And at that point, they will be able to penetrate the kernel, and from there, break security of other processes.
So if you want that kind of security isolation, you shouldn’t be using containers in the first place. You should be using KVM or Xen, and then only after spending a huge amount of effort fuzz testing the KVM/Xen paravirtualization interfaces.
Kernel developer Greg Kroah-Hartman wrote,
Containers are not necessarily a “security” boundary, there are many “leaks” across it, and you should use it only as a way to logically partition off users/processes in a way that makes it easier to manage and maintain complex systems. The container model is quite powerful and tools like docker and systemd-nspawn provide a way to run multiple “images” at once in a very nice way.
Containers are powerful tools for Linux administrators, but for true multi-tenant cloud installations, we need stricter isolation between tenants.
Containerization is not “free”. For instance, the Linux Memory Controller can slow down the kernel by as much as 15%, just by being enabled, with no users. The Memory Controller itself is complicated, but cgroups controllers, on which it depends, are also complex. The surface of change is just way too big, and the resulting implementation necessarily too complex. George Dunlap said it best,
With containers you’re starting with everything open and then going around trying to close all the holes; if you miss even a single one, bam, you lose. With VMs, you start with almost everything closed, and selectively open things up; that makes a big difference.
This is part 2 of a 3-part series. Please subscribe to our feed or follow @CloudiusSystems to get a notification when part 3 is available.