
By Glauber Costa and Don Marti
We’re planning to attend the Linux Foundation’s CloudOpen North America conference. Hope to see you there, and please come to our talk, “Beating the Virtualization Tax for NoSQL Workloads With OSv.”
We’ll be using a popular NoSQL database for our demo: Redis. If you’d like to follow along, you’re welcome to clone and build Redis on OSv. We’re big Redis fans, because it’s a fast, easy-to-administer, in-memory database that works with many useful data structures.
Redis A to Z
Redis is a remarkably useful piece of software. People on the Internet talk about Redis a lot. Here’s what Google Suggest has to say about it: Atomic, benchmark, cluster, delete, expire, failover, gem, hash, incr, Java, key, list, master/slave, node.js, objects, Python, queue, Ruby, set, ttl, Ubuntu, “vs. mongodb”, Windows, XML, yum, zadd. (zadd is a really cool command by the way. A huge time-saver for maintaining “scoreboard” state for games and content-scoring applications. Did we mention that we’re Redis fans?)
Redis fills a valuable niche between memcached and a full-scale NoSQL database such as Cassandra. Although it’s fast and perfectly usable as a simple key-value store, you can also use Redis to manage more featureful data structures such as sets and queues.
It makes a great session cache, lightweight task queue, or a place to keep pre-rendered content or ephemeral data, and it’s a star at highscalability.com.
But you probably already know that.
Building Redis on OSv
Redis works normally on OSv except for one feature: the BGSAVE command. A Redis background save depends on the operating system’s copy-on-write functionity. When you issue the BGSAVE command, the parent Redis process calls fork, and the parent process keeps running while the child process saves the database state.
Copy-on-write ensures that the child process sees a consistent set of data, while the parent gets its own copy of any page that it modifies.
Because OSv has a single address space, that isn’t an option here. OSv support Redis SAVE but not BGSAVE. Other than that, running redis on OSv requires little effort. From the OSv source tree, all one should do is:
make image=redis-memonly
Now you have a usr.img file, which you can run locally with OSv’s run.py. Behind the scenes, all that this build step is doing is to issue the application’s make, with the right set of flags so redis is a shared library. For more info on how to do that, see our earlier example. of how to use the -fPIC and -shared options.
Is it fast?
We have been running redis on local machines to test many of its functionalities and help us mature OSv. As with any piece of software, the result of course depends on many factors. Because OSv is an operating system designed for the cloud, we wanted to showcase its performance running on Amazon EC2.
To do that, we have selected the c3.x8large machines. They feature 32 CPUs and 60Gb of memory each. We are fully aware this is an overkill in the case of Redis - a single threaded application. However, those are the only machines that Amazon advertises as featuring 10Gb networking, and we didn’t want the network to be a bottleneck for the sake of the benchmark. Also, smaller machines cannot be put in EC2 placement groups. It all boils down to the network!
So in this benchmark, no more than two cores should be active at any given time - one for redis, one for network interrupt processing. In a real scenario, one could easily deploy in a smaller machine.
Benchmark setup
We have benchmarked redis’ latest beta (beta-8) running both on OSv, and on an Ubuntu14 AMI. To do that, we have just launched a new AMI, selected Ubuntu14.04, and launched it. Once it launched, we have downloaded and compiled redis’ latest, and moved the redis.conf used by OSv to the machine. The only difference in that configuration file from what is shipped with redis by default, is that we disable disk activity. As already explained, OSv currently do not support that, and to be fair, the Linux guest we are comparing against should not hit the disk either at any point.
On ubuntu, redis was run with:
numactl --physcpubind=1 redis-server ~/redis.conf
Using numactl considerably reduces the standard deviation coming from the Linux scheduler moving the thread around.
The redis-benchmark command was issued in another machine of the same type,
running in the same zone and placement group.
The two commands were:
numactl --physcpubind=1 redis-benchmark --csv -h <IP> -c 50 -n 100000 -P 1
and later on, to demonstrate how OSv can handle larger messages,
numactl --physcpubind=1 redis-benchmark --csv -h <IP> -c 50 -n 100000 -P 16
What this last command does, is to exercise redis’ pipeline feature, that
can send multiple - in this case 16 - commands in the same packet. This will
decrease the impact of the round trip time in the final figure.
The difference can be clearly seen in the graph…
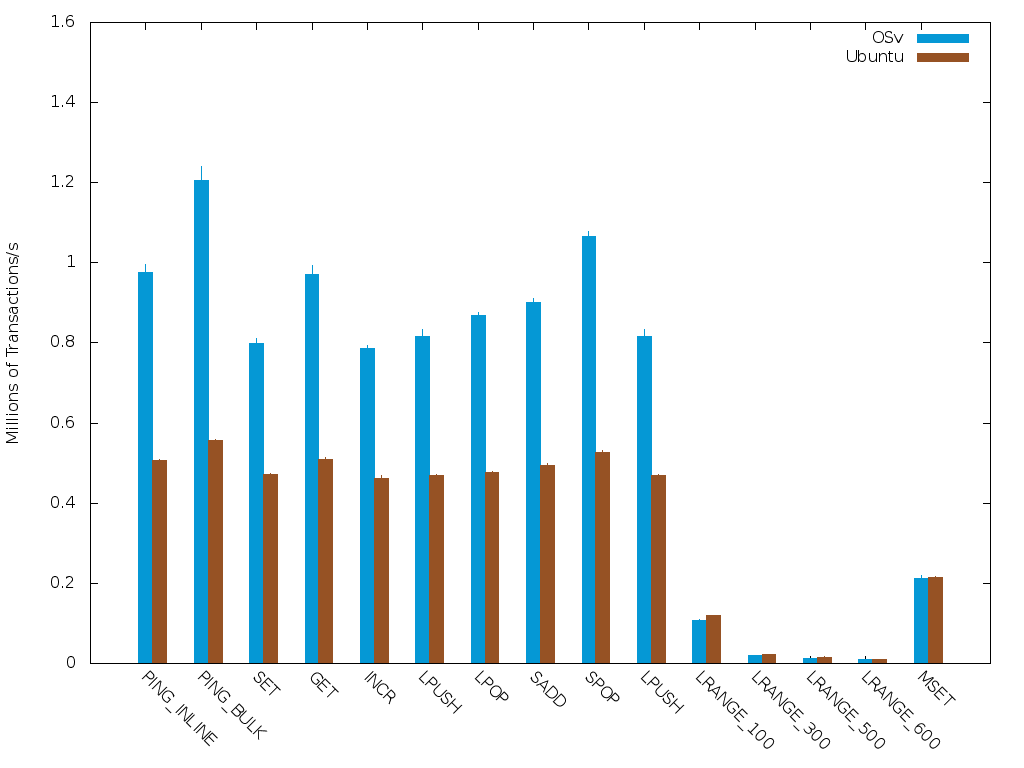
Note that the LRANGE class of commands has a significantly different pattern than the other commands. In that command, the client sends a very short query, and receive a potentially very large reply, thereby exercising the transmission path, rather than the receive path of OSv. This table shows that our transmission path is lacking a bit of love, particularly when the response sizes grows (as the pipeline level increases)
Conclusions
OSv is a fast maturing, but not yet mature operating system, soon to be in beta phase. We have gaps to close, as can be seen in the case of LRANGE set of benchmarks. So far, we have focused our efforts in technologies around the receive path, and it has paid off: We can offer a level of performance far beyond what an out of the box distribution can. Some features that we architecturally lack, makes the use of Redis as a full-blown on-disk database challenging. But if you want to serve your load from memory, the OSv promise delivers: With OSv, you don’t have to pay the virtualization tax.
If you’ll be at CloudOpen, you can add our talk to your schedule now.
If you have any questions on running Redis or any other application, please join the osv-dev mailing list. You can get general updates by subscribing to this blog’s feed, or folllowing @CloudiusSystems on Twitter.